记一次vite项目打包优化
新项目是使用vite作为开发工具的,最近发现vite项目的构建存在一些优化的空间,比如构建时间、构建产物的体积、缓存命中等,经过一番折腾之后达到了还不错的效果,记录一下。
参考:
现状
项目使用vite@4.0.0,vite本身没有构建的能力,build是通过rollup来完成的,rollup主要的工作是用于打包lib包,构建生产环境的文件并不如webpack那么强大,只有通过output.manualchunks来手动指定chunk
默认,在不配置 manualchunks的情况下,rollup会将每个模块文件打包成一个单独的js文件,不会对chunk进行合并,这会导致chunk 数量太多(触发同域名网络请求最大数量限制),部分chunk文件内容少(不到1kb,代码混淆没有意义)。
由于是项目初期,代码还不是很多,构建策略比较简单,使用vite文档里面提到的早期默认策略,即将 chunk 分割为 index 和 vendor
- node_modules里面的包打在vendor里面
- 业务代码放在index里面
manualChunks: (id: string) => {
if (id.includes('node_modules')) {
return 'vendor'
}
return 'index'
},这么构建也存在一些弊端
- 最后产物只有这两个文件,动态路由文件等不会额外产出文件了,首屏加载时间长
- 业务代码经常迭代,导致index文件无法使用缓存
- 构建时需要合并代码,CI打包时间较长
此外,整个项目在架构上的设计也导致了一些打包问题。
项目采用monorepo架构,包含移动端和pc端两个application包,以及多个公共的package包。有的package没有提供按需加载的功能,在index入口文件暴露了只在某一端使用的方法,这就导致了另一端的构建产物会包含一些额外无用的代码,导致包的体积变大。
因此,本次优化需要解决下面几个问题
- 优化构建产物,包括体积、加载速度、缓存命中率等
- 控制chunk数量
- 提高CI构建速度
OK,介绍完背景,接下来就是研究如何进行优化了。
优化
配置visualizer插件,这样可以在打包后查看构建产物的具体情况
import { visualizer } from 'rollup-plugin-visualizer'
export default defineConfig({
build: {
rollupOptions: {
plugins: [visualizer({ open: true })],
},
},
})然后执行npm run build,构建完成后会在项目根目录生成一个stats.html,浏览器打开这个文件就可以看见具体的信息,同时控制台也会输出构建时间。这样,就可以测试每次修改之后构建的实际效果。
由于要修改manualChunks的策略,于是先将其配置注释掉,从vite默认配置的输出产物进行分析
分析chunk数量
重新构建,可以看到,一些依赖的模块如swpier、photoswip等都进行了单独打包,,每个sfc组件文件也被单独构建,出现了很多几kb的文件
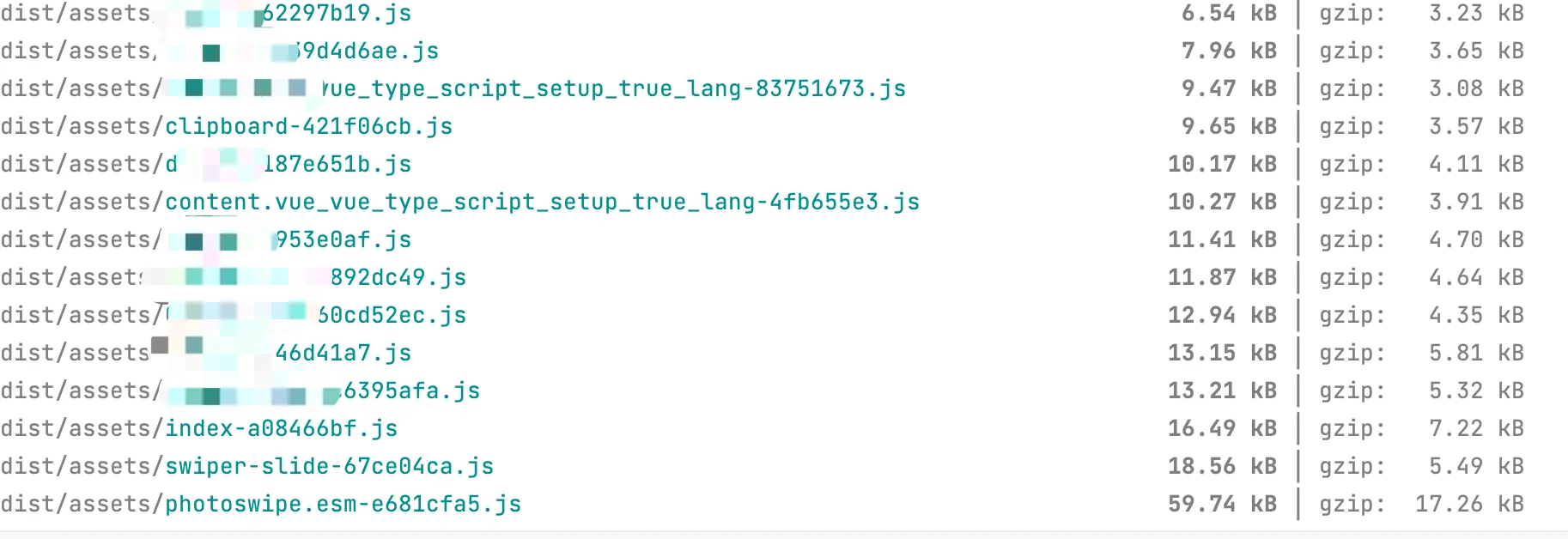
除了js文件,还发现sfc组件里面的style也被拆成了独立的css文件。由于整个项目使用了windicss原子类框架,因此产生的css文件会比常规的scoped css项目里面少很多

所有的静态资源最后都会上传到CDN上,服务器只部署了html文件。目前只使用了一个cdn域名,通过vite的base配置项指定。
chunk数量多带来的最大问题是浏览器对同域名网络请求有最大数量限制。
首先,这个限制会导致资源加载需要更长的时间。以Chrome为例,这个限制为6,当同域名同时请求的资源文件数量大于6时,后面的文件就会进入pending状态,直到前面的文件加载完毕后释放了额外的资源才会进入下载状态
其次,由于css的下载会阻塞后续DOM的渲染,css标签一般会放在head里面同步加载,如果待下载的css资源被阻塞了,用户首次看见内容之前的页面白屏时间就会更长。
在文章开头,为了解决这个问题,使用了默认策略合并文件,最后只产出vendor和index两个文件(css和js各两个),这样会极大程度地减少chunk的数量,但也带来了那几个提到的需要解决的问题。
关于rollup的code split,建议先看看这个issue的讨论,里面讨论了rollup是否能够支持像webpacksplitChunks.minSize类似的配置项,将小于某个尺寸的所有chunk进行合并
看完之后,大概就知道了rollup在3.3之后的版本提供了一个实验性质的配置项output.experimentalMinChunkSize,来合并小chunk,
build: {
rollupOptions: {
output: {
experimentalMinChunkSize: 20*1024, // 单位b
},
},
},如果chunk小于这个值,则会尝试与其他的chunk进行合并。但是如果模块存在副作用(如console.log等),则不会进行合并。
是否有必要减少chunk数量
在探究新的解决方案之前,我们来思考一下,多chunk的打包策略,除了加载时的限制之外,还有其他的问题,或者优点吗?
在还没有前端工程化的时候,一个页面天然就需要多个script来引入多个库文件
<script src="https://xxx.cdn.com/jquery.min.js"></script>
<script src="https://xxx.cdn.com/vue.umd.js"></script>
<script src="https://xxx.cdn.com/index.js"></script>
<script src="https://xxx.cdn.com/comp1.js"></script>每个文件单独引入,在缓存、按需加载等问题上都比bundle(打包到一个文件)有很大的优势。
- 缓存可以精确到单个链接上,比如修改了comp1的代码,只会重新加载
comp1.js,而不会影响index.js - 每个页面只需要引入自己依赖的小体积文件(而不是一个all in one 的bundle 文件),同时可以尽可能地服用其他页面已经加载过的文件缓存,不会有一丁点额外的浪费
那么,我们为什么还需要all in one的 打包策略呢?细想一下,好像也只能说出并发请求数量限制这一个缺点
但事实上,在2023年的今天,早就已经可以使用HTTP/2,通过多路复用的特性来避免每个资源都占用一个TCP链接导致浏览器的最大并发请求限制的问题了!
在HTTP1.x中,如果想并发多个请求,必须使用多个 TCP 链接,浏览器为了控制资源,才会有单个域名有 6-8个的TCP链接请求限制
HTTP2的多路复用特性允许单一的连接可以发送多重的请求和响应,充分的利用TCP,同时HTTP2可以在客户端和服务器端维护静态字典和动态字典用来压缩和差量更新HTTP头部,大大降低因头部传输产生的流量
- 同域名下所有通信都在单个连接上完成。
- 单个连接可以承载任意数量的双向数据流。
- 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。
这样一来,同个域名只需要占用一个 TCP 连接,浏览器也不用再限制同域名并发请求的。
因此,我决定尝试一下多chunk的打包策略,结合CDN HTTP2避免网络加载问题。
开启CDN的HTTP2也比较简单,主流CDN厂商都提供了相关的配置,比如阿里云对应的文档

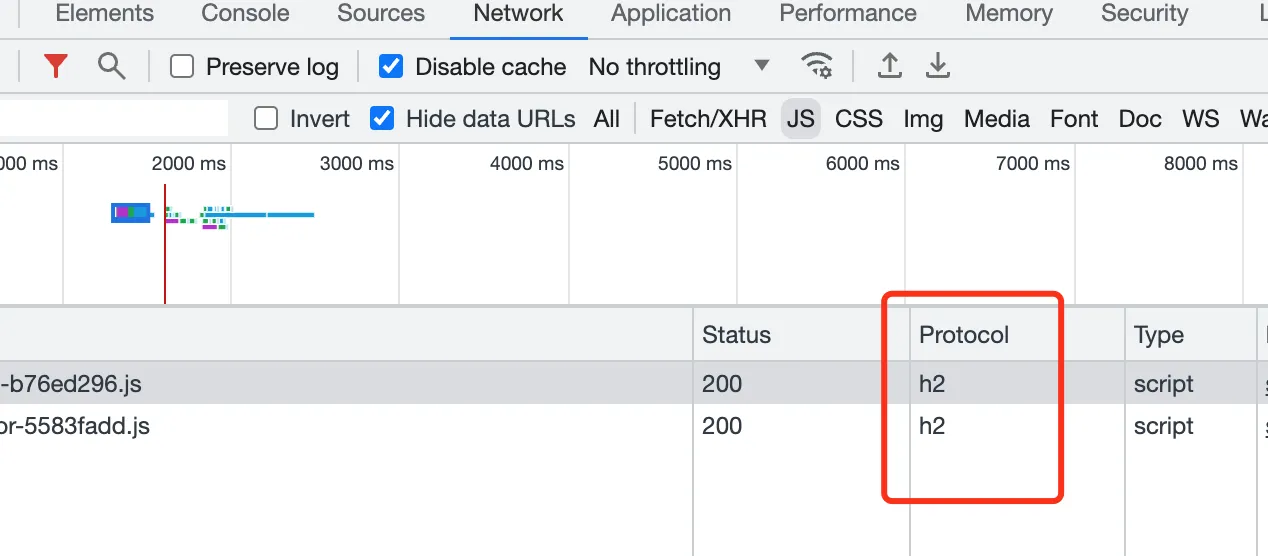
点击一下即可开启。开启之后,打开浏览器控制台,在资源对应的Protocol处可以查看,如果展示的是h2,就说明HTTP2已经成功开启
是否有必要合并第三方依赖
整个项目没有使用SSR,而是纯SPA。目前,主流搜索引擎已经开始逐步支持抓取JavaScript渲染的内容了,参考
爬虫机器人抓取JavaScript渲染页面的大致流程为
- 下载HTML文档
- 下载文档中依赖的CSS和JavaScript
- 使用WRS渲染器,Indexer 的一部分)解析、编译并执行JavaScript
- WRS 从外部API、资料库获取资料(data)
- 一系列解析之后,收录页面内容
在issue这个文档中提到,由于chunk数量太多,导致Google收录站点存在问题。
虽然我们的项目目前并没有过多考虑SEO,但还是可以尝试控制一下chunk数量。我想到的策略是:将node_modules中第三方lib打包到一个vendor里面,业务代码维持单chunk,通过HTTP2保证页面加载速度。
这么做的原因是
- 第三方依赖包一般是整个项目依赖的基础,比如vue、pinia、axios等,比较稳定,构建出来的vendor一般不会发生变化(除非删除或增加了依赖)
- 业务代码使用单chunk,可以最大程度地实现按需加载
当我按照这个策略进行了修改之后
manualChunks: (id: string) => {
if (id.includes('node_modules')) {
return 'vendor'
}
},数十个外部依赖包合并到了同一个vendor文件中,看起来达到效果了。
但在分析输出产物的时候发现,只有极少数页面用到的第三方依赖包也打到了vendor里面(比如只有某个活动页面使用到了html2canvas这个库),造成vendor的体积变大。
针对这种需要按需加载的第三方库,可以在manualChunks中单独配置一下
manualChunks: (id: string) => {
// 只有极少数活动页面使用了这个库,单独处理
if (id.includes('html2canvas')) {
return 'html2canvas'
}
if (id.includes('node_modules')) {
return 'vendor'
}
},本地package的导出优化
前面提到了项目采用的是monorepo架构,本地包没有提供按需加载的功能,导致部分端特定的代码冗余。
举个例子,假设packageA在index.js中导出了两个组件
export { default as Comp1 } from './Comp1.vue'
export { default as Comp2 } from './Comp2.vue'在使用时,通过下面的方式引入
// pc端
import { Comp1, Comp2 } from '@project/packageA'
// 移动端
import { Comp1 } from '@project/packageA'目前,Comp1是移动端和PC端公用的组件,而Comp2只在PC端使用,但这样导出会导致移动端也会将Comp2的代码进行打包,Comp2中依赖的第三方库也会被打进vendor里面。
解决办法就是按需加载,按需导出需要借助通过package.json中的exports定义子文件模块,参考文档Conditional exports
首先,我们将需要导出的模块放在单独的文件里面
// /packageA/src/lib/comp1.ts
export { default as Comp1 } from './Comp1.vue'
// /packageA/src/lib/comp2.ts
export { default as Comp2 } from './Comp2.vue'然后通过exports导出文件
"exports": {
".": {
"types": "./src/index.ts",
"import": "./src/index.ts",
"require": "./src/index.ts"
},
"./lib/*": {
"types": "./src/lib/*.ts",
"import": "./src/lib/*.ts",
"require": "./src/lib/*.ts"
}
},这样,在应用文件里面,就可以通过下面的方式引入依赖
import {Comp1} from '@project/packageA/lib/comp1'
import {Comp2} from '@project/packageA/lib/comp2'由于移动端不会引入Comp2,也就不会将其中的代码进行打包了,对于打包速度和产物体积都有一定程度的优化。
遇见的一个问题时,在构建的时候,typescript会提示找不到模块,参考这个issue
解决办法是将tsconfig的compilerOptions.moduleResolution指定到node16或nodenext,这会带来一个新的问题:node16需要在import的时候指定文件后缀,很多历史模块都会受到影响
因此,折中的办法就是通过配置tsconfig的path字段,手动指定一下模块的具体路径
"paths": {
"@project/packageA/lib/*": [
"./node_modules/packageA/src/lib/*"
]
}至此,在monorepo架构中,每个应用包也可以按需加载自定义的package了
小结
因此,最后的构建策略是
- node_modules中的第三方依赖,统一合并到vendor文件,少数需要按需加载的包,单独构建chunk
- 业务代码,单独构建chunk,配合CDN开启HTTP2的方式,保证页面加载速度
- monorepo中的公共包,按需导出,避免引入冗余代码
以移动端应用为例,对比一下优化之前的数据

优化之后的数据

构建时间减少了14s,首次需要加载的文件体积更是缩小了近900kb(1410+714 - 999-236),更重要的是开启了HTTP2,后续代码更新的时候,可以最大程度地复用缓存,加载速度可以进一步提升。
目前整个改动已经部署到了生产环境,先观察一段时间的数据,后面有啥问题再记录。
你要请我喝一杯奶茶?
版权声明:自由转载-非商用-保持署名和原文链接。
本站文章均为本人原创,参考文章我都会在文中进行声明,也请您转载时附上署名。
